

Este artículo forma parte de nuestra serie Scaling Kubernetes. Regístrese en para verlo en directo o acceder a la grabación, y consulte nuestros otros artículos de esta serie:
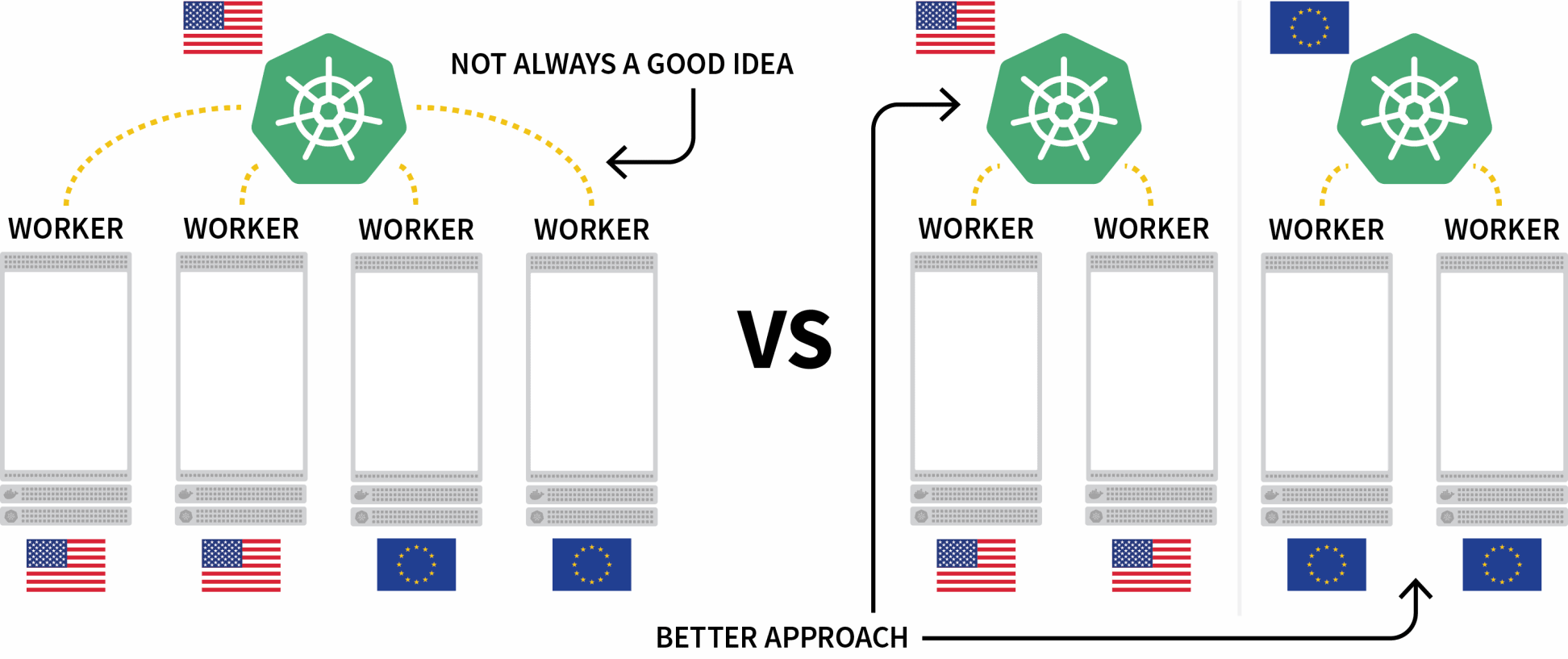
Un reto interesante de Kubernetes es el despliegue de cargas de trabajo en varias regiones. Aunque técnicamente se puede tener un clúster con varios nodos ubicados en diferentes regiones, en general se considera que es algo que se debe evitar debido a la latencia adicional.
Una alternativa popular es desplegar un clúster para cada región y encontrar la manera de orquestarlos.
En este post, lo harás:
- Crear tres agrupaciones: una en Norteamérica, otra en Europa y otra en el Sudeste Asiático.
- Crea un cuarto clúster que actuará como orquestador de los demás.
- Configure una única red de las tres redes de clúster para una comunicación fluida.
Este post ha sido programado para trabajar con Terraform requiriendo una interacción mínima. Puedes encontrar el código en el GitHub de LearnK8s.
Creación del gestor de clústeres
Empecemos por crear el clúster que gestionará el resto. Los siguientes comandos se pueden utilizar para crear el clúster y guardar el archivo kubeconfig.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-cluster-managerPuede comprobar que la instalación se ha realizado correctamente con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-cluster-manager¡Excelente!
En el gestor de clústeres, instalará Karmada, un sistema de gestión que le permite ejecutar sus aplicaciones nativas de la nube en varios clústeres y nubes Kubernetes. Karmada tiene un plano de control instalado en el gestor de clústeres y el agente instalado en todos los demás clústeres.
El plano de control tiene tres componentes:
- Un servidor API ;
- Un Controller Manager; y
- Un programador

Si te resultan familiares, es porque el plano de control de Kubernetes incluye los mismos componentes. Karmada tuvo que copiarlos y aumentarlos para que funcionaran con varios clústeres.
Ya está bien de teoría. Vayamos al código.
Utilizaremos Helm para instalar el servidor Karmada API . Añadamos el repositorio Helm con:
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/chartsDado que el servidor de Karmada API debe ser accesible para todos los demás clústeres, tendrá que
- exponerlo desde el nodo; y
- asegúrese de que la conexión es de confianza.
Así que vamos a recuperar la dirección IP del nodo que aloja el plano de control con:
bash
kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type==\"ExternalIP\")].address}' \
--kubeconfig=kubeconfig-cluster-managerAhora puede instalar el plano de control de Karmada con:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-cluster-manager \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set apiServer.hostNetwork=false \
--set apiServer.serviceType=NodePort \
--set apiServer.nodePort=32443 \
--set certs.auto.hosts[0]="kubernetes.default.svc" \
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[3]="*.karmada-system.svc" \
--set certs.auto.hosts[4]="localhost" \
--set certs.auto.hosts[5]="127.0.0.1" \
--set certs.auto.hosts[6]="<insert the IP address of the node>"Una vez finalizada la instalación, puede recuperar el kubeconfig para conectarse a Karmada API con:
bash
kubectl get secret karmada-kubeconfig \
--kubeconfig=kubeconfig-cluster-manager \
-n karmada-system \
-o jsonpath={.data.kubeconfig} | base64 -d > karmada-configPero espera, ¿por qué otro archivo kubeconfig?
Karmada API está diseñado para reemplazar el estándar de Kubernetes API pero aún conserva toda la funcionalidad a la que está acostumbrado. En otras palabras, puede crear despliegues que abarquen varios clústeres con kubectl.
Antes de probar Karmada API y kubectl, debe parchear el archivo kubeconfig. Por defecto, el kubeconfig generado solo puede utilizarse desde dentro de la red del clúster.
Sin embargo, puede sustituir la siguiente línea para que funcione:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncatedSustitúyala por la dirección IP del nodo que recuperó anteriormente:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncatedGenial, es hora de probar Karmada.
Instalación del agente de Karmada
Emita el siguiente comando para recuperar todas las implantaciones y todos los clústeres:
bash
$ kubectl get clusters,deployments --kubeconfig=karmada-config
No resources foundComo era de esperar, no hay despliegues ni clusters adicionales. Agreguemos algunos clusters más y conectémoslos al plano de control de Karmada.
Repita los siguientes comandos tres veces:
bash
linode-cli lke cluster-create \
--label <insert-cluster-name> \
--region <insert-region> \
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>Los valores deben ser los siguientes:
- Nombre del clúster
eu, regióneu-west y el archivo kubeconfigkubeconfig-eu - Nombre del clúster
ap, regiónap-southy el archivo kubeconfigkubeconfig-ap - Nombre del clúster
us, regiónus-westy el archivo kubeconfigkubeconfig-us
Puede comprobar que los clusters se han creado correctamente con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-eu
$ kubectl get pods -A --kubeconfig=kubeconfig-ap
$ kubectl get pods -A --kubeconfig=kubeconfig-usAhora es el momento de hacer que se unan a la agrupación de Karmada.
Karmada utiliza un agente en cada dos clústeres para coordinar el despliegue con el plano de control.

Utilizará Helm para instalar el agente Karmada y vincularlo al gestor de clústeres:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set installMode=agent \
--set agent.clusterName=<insert-cluster-name> \
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority> \
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data> \
--set agent.kubeconfig.key=<karmada kubeconfig client key data> \
--set agent.kubeconfig.server=https://<insert node's IP address>:32443 \Tendrás que repetir el comando anterior tres veces e insertar las siguientes variables:
- El nombre del clúster. Puede ser
eu,apous - La autoridad de certificación del cluster manager. Puede encontrar este valor en el archivo
karmada-configarchivounder clusters[0].cluster['certificate-authority-data'].
Puede descodificar el valor de base64. - Los datos del certificado de cliente del usuario. Puede encontrar este valor en el campo
karmada-configarchivar enusers[0].user['client-certificate-data'].
Puede decodificar el valor de base64. - Los datos del certificado de cliente del usuario. Puede encontrar este valor en el campo
karmada-configarchivar enusers[0].user['client-key-data'].
Puede decodificar el valor de base64. - Dirección IP del nodo que aloja el plano de control de Karmada.
Para verificar que la instalación se ha completado, puede ejecutar el siguiente comando:
bash
$ kubectl get clusters --kubeconfig=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull True¡Excelente!
Orquestación de la implementación multiclúster con políticas de Karmada
Con la configuración actual, usted envía una carga de trabajo a Karmada, que la distribuirá entre los demás clústeres.
Vamos a probarlo creando un despliegue:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: helloPuede enviar el despliegue al servidor de Karmada API con:
bash
$ kubectl apply -f deployment.yaml --kubeconfig=karmada-configEste despliegue tiene tres réplicas, ¿se distribuirán por igual entre los tres clústeres?
Comprobémoslo:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0¿Por qué Karmada no crea las vainas?
Describamos el despliegue:
bash
$ kubectl describe deployment hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resourceKarmada no sabe qué hacer con los despliegues porque no has especificado una política.
El planificador de Karmada utiliza políticas para asignar cargas de trabajo a los clusters.
Definamos una política sencilla que asigne una réplica a cada clúster:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1Puede enviar la política al clúster con:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configInspeccionemos los despliegues y los pods:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
Karmada asignó un pod a cada cluster porque su política definió un peso igual para cada cluster.
Vamos a escalar el despliegue a 10 réplicas con:
bash
$ kubectl scale deployment/hello --replicas=10 --kubeconfig=karmada-configSi inspecciona las vainas, puede encontrar lo siguiente:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0Modifiquemos la política para que las agrupaciones de la UE y EE.UU. se queden con el 40% de las vainas y sólo el 20% quede para la agrupación de AP.
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2Puede presentar la póliza con:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configPodrá observar cómo cambia la distribución de su vaina:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubeconfig=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubeconfig=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s
¡Genial!
Karmada soporta varias políticas para distribuir sus cargas de trabajo. Puede consultar la documentación para casos de uso más avanzados.
Los pods se están ejecutando en los tres clusters, pero ¿cómo se puede acceder a ellos?
Inspeccionemos el servicio en Karmada:
bash
$ kubectl describe service hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.El servicio está desplegado en los tres clusters, pero no están conectados.
Aunque Karmada puede gestionar varios clústeres, no proporciona ningún mecanismo de red para asegurarse de que los tres clústeres estén vinculados. En otras palabras, Karmada es una excelente herramienta para orquestar despliegues a través de clústeres, pero se necesita algo más para asegurarse de que esos clústeres puedan comunicarse entre sí.
Conexión de clústeres múltiples con Istio
Istio suele utilizarse para controlar el tráfico de red entre aplicaciones del mismo clúster. Funciona interceptando todas las solicitudes salientes y entrantes y proxyándolas a través de Envoy.

El plano de control de Istio se encarga de actualizar y recopilar métricas de esos proxies y también puede emitir instrucciones para desviar el tráfico.

Así que usted podría utilizar Istio para interceptar todo el tráfico a un servicio en particular y dirigirlo a uno de los tres clusters. Esa es la idea con la configuración multiclúster de Istio.
Basta de teoría, vamos a ensuciarnos las manos. El primer paso es instalar Istio en los tres clústeres.
Aunque hay varias formas de instalar Istio, yo suelo preferir Helm:
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/chartsPuede instalar Istio en los tres clusters con:
bash
$ helm install istio-base istio/base \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace istio-system \
--version=1.14.1Debe sustituir el cluster-name con ap, eu y us y ejecute el comando para cada uno.
El gráfico base instala principalmente recursos comunes, como Roles y RoleBindings.
La instalación propiamente dicha se realiza en el paquete istiod gráfico. Pero antes de proceder con eso, usted tiene que configurar la Autoridad de Certificación (CA) de Istio para garantizar que los tres clusters puedan conectarse y confiar entre sí.
En un nuevo directorio, clona el repositorio Istio con:
bash
$ git clone https://github.com/istio/istioCrear un certs y cambie a ese directorio:
bash
$ mkdir certs
$ cd certsCrear el certificado raíz con:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-caEl comando generó los siguientes archivos:
root-cert.pemel certificado raíz generadoroot-key.pemla clave raíz generadaroot-ca.conf: la configuración para que OpenSSL genere el certificado raízroot-cert.csrel CSR generado para el certificado raíz
Para cada clúster, genere un certificado y una clave intermedios para la autoridad de certificación de Istio:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacertsLos comandos generarán los siguientes archivos en un directorio llamado cluster1, cluster2y cluster3:
bash
$ kubectl create secret generic cacerts -n istio-system \
--kubeconfig=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem \
--from-file=<cluster-folder>/ca-key.pem \
--from-file=<cluster-folder>/root-cert.pem \
--from-file=<cluster-folder>/cert-chain.pemDebe ejecutar los comandos con las siguientes variables:
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |Una vez hecho esto, ya puedes instalar istiod:
bash
$ helm install istiod istio/istiod \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set global.meshID=mesh1 \
--set global.multiCluster.clusterName=<insert-cluster-name> \
--set global.network=<insert-network-name>Debes repetir el comando tres veces con las siguientes variables:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |También debe etiquetar el espacio de nombres Istio con una anotación de topología:
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubeconfig=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubeconfig=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubeconfig=kubeconfig-eu¿Eso es todo?
Casi.
Tunelización del tráfico con una pasarela Este-Oeste
Aún lo necesitas:
- una pasarela para canalizar el tráfico de un clúster a otro; y
- un mecanismo para descubrir direcciones IP en otros clusters.

Para la pasarela, puede utilizar Helm para instalarla:
bash
$ helm install eastwest-gateway istio/gateway \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set labels.istio=eastwestgateway \
--set labels.app=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set networkGateway=<insert-network-name> \
--set service.ports[0].name=status-port \
--set service.ports[0].port=15021 \
--set service.ports[0].targetPort=15021 \
--set service.ports[1].name=tls \
--set service.ports[1].port=15443 \
--set service.ports[1].targetPort=15443 \
--set service.ports[2].name=tls-istiod \
--set service.ports[2].port=15012 \
--set service.ports[2].targetPort=15012 \
--set service.ports[3].name=tls-webhook \
--set service.ports[3].port=15017 \
--set service.ports[3].targetPort=15017 \Debes repetir el comando tres veces con las siguientes variables:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |A continuación, para cada clúster, exponga un Gateway con el siguiente recurso:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"Puedes enviar el archivo a los clusters con:
bash
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-usPara los mecanismos de descubrimiento, es necesario compartir las credenciales de cada clúster. Esto es necesario porque los clústeres no se conocen entre sí.
Para descubrir otras direcciones IP, deben acceder a otros clústeres y registrarlos como posibles destinos del tráfico. Para ello, debe crear un secreto de Kubernetes con el archivo kubeconfig para los otros clústeres.
Istio los utilizará para conectarse a los demás clústeres, descubrir los puntos finales y ordenar a los proxies Envoy que reenvíen el tráfico.
Necesitarás tres secretos:
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>Debes crear los tres secretos con las siguientes variables:
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |Ahora debes enviar los secretos al cluster prestando atención a no enviar el secreto AP al cluster AP.
Los comandos deben ser los siguientes:
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-eu¡Y eso es todo!
Ya está listo para probar la configuración.
Prueba de la red multiclúster
Vamos a crear un despliegue para un pod de sueño.
Utilizará este pod para realizar una petición al despliegue Hello que creó anteriormente:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: truePuede crear el despliegue con:
bash
$ kubectl apply -f sleep.yaml --kubeconfig=karmada-configDado que no existe una política para esta implementación, Karmada no la procesará y la dejará pendiente. Puede modificar la política para incluir el despliegue con:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1Puede aplicar la política con:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configPuede averiguar dónde se desplegó el pod con:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
$ kubectl get pods --kubeconfig=kubeconfig-ap
$ kubectl get pods --kubeconfig=kubeconfig-usAhora, suponiendo que el pod aterrizó en el clúster de EE.UU., ejecute el siguiente comando:
Now, assuming the pod landed on the US cluster, execute the following command:
bash
for i in {1..10}
do
kubectl exec --kubeconfig=kubeconfig-us -c sleep \
"$(kubectl get pod --kubeconfig=kubeconfig-us -l \
app=sleep -o jsonpath='{.items[0].metadata.name}')" \
-- curl -sS hello:5000 | grep REGION
doneQuizá observe que la respuesta procede de diferentes vainas de distintas regiones.
¡Trabajo hecho!
¿Qué hacer a partir de ahora?
Esta configuración es bastante básica y carece de varias funciones más que probablemente quieras incorporar:
- podrías exponer un Istio ingress desde cada cluster para ingerir el tráfico;
- podría utilizar Istio para dar forma al tráfico de modo que se prefiera el tráfico local; y
- es posible que desee utilizar reglas de aplicación de políticas de Istio para definir cómo puede fluir el tráfico entre los clústeres.
Recapitulemos lo tratado en este artículo:
- utilizando Karmada para controlar varios clusters;
- definir políticas para programar las cargas de trabajo en varios clústeres;
- el uso de Istio para conectar en red varios clústeres; y
- cómo Istio intercepta el tráfico y lo reenvía a otros clusters.
Puede ver un recorrido completo del escalado de Kubernetes en distintas regiones, además de otras metodologías de escalado, registrándose en nuestra serie de seminarios web y viéndolos a petición.



Comentarios